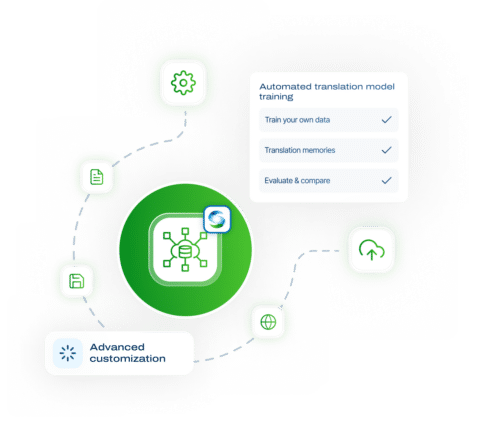
SYSTRAN Model Studio
独自の 翻訳モデルの作成
独自のデータや翻訳メモリを使用してトレーニングされた独自のカスタマイズされた翻訳モデルを作成し、翻訳の生産性を大幅に向上させます。

翻訳メモリを使用して 翻訳モデルを適合させる

評価
モデルのスコアを 評価して比較する
独自のテストセットを追加するか、 データのアップロード段階でテストと評価のために トレーニングデータの一部を割り当てることを選択できます。
SYSTRANの 幅広いカタログを活用する
翻訳モデルをゼロから構築するのは困難ですが、幸いにもあなたはゼロから始める必要はありません。シストランは何十年もの経験を持ち、AI翻訳のリーダーとして、幅広い翻訳モデルのノウハウを持っています
最初に、SYSTRANのカタログから既存のモデルを選択し、その後、独自のデータでカスタマイズすることができます。50以上の言語や法律、医療、金融、ITなどの人気のあるドメインの数十ものモデルが利用可能です!

WEBINAR
Model Studio : 簡単で迅速かつカスタマイズされた翻訳モデルトレーニング
翻訳出力の品質を向上させるには、 カスタマイズが不可欠であり、Model Studioはまさにそれが実現できるソリューションです。
このウェビナーでは、プロダクトオーナーのGuersande ChaminadeとシストランのアカウントマネージャーStéphanie Labroueが、 SYSTRAN Model Studioで独自のカスタム翻訳モデルの作成方法 について説明します。

カスタマイズ
各業界に合わせた翻訳ソリューションを提供
電子情報分析捜査
政府機関向け多言語情報分析
多言語コミュニケーション
カスタマーサポート
ローカライゼーション
NFA機能とは?
NFA, short for Neural Fuzzy Adaptation, is a powerful feature that enables our engine to translate guided by the index. When translators post-edit new segments, the system incorporates these changes on-the-fly, continuously improving the translation quality.
You can learn more about NFA with two of our latests webinar, one with XTM and the other one with MemoQ
BLEUスコアはターゲット言語の評価にのみ使用しますか?
現時点では、ModelStudioはBLEUスコアのみを表示します。Cometのような他のツールを取り入れることに積極的に取り組んでいますが、当面の主な評価指標としてBLEUスコアを使用することの効率性と使いやすさに焦点を当てています。
SYSTRAN translate ServerとSYSTRAN translate Private Cloudなど複数のモデルを同時に展開できますか?
Absolutely! You can deploy multiple models and choose the one that best fits your specific project. Before deploying a model, you can also utilize the evaluation feature, which allows you to upload and compare various test files to see how each model performs.
You can compare up to three models side by side, making it easy to find the ideal fit for your requirements.
But even without using this feature, you can easily deploy more than one model.
最大100万セグメントの制限とは?
Model Studioは、最大100万文ペアを最大限に活用するように設計されており、データのクリーンさと堅牢性の両面でその制限が適用されます。この制限は、データの重複排除や潜在的な文字の破損を抑制した後のものに適用されます。
また、ネットワークの問題を避けるために、非常に大きなファイルを一度にアップロードしないことをお勧めします。
トレーニングデータでマークアップタグはどのように処理されますか?
At the moment, the handling of tags and placeholders can be challenging. Long sentences containing tags may be deleted to improve processing. However, we’re actively working on solutions to better handle tags, and this feature is expected to be available in 2024.
In the meantime, you can enter your tags into your CatTools and let these CatTools handle them.
トレーニングデータは匿名化されますか?
As seen before, and as placeholders may be considered as tag, using placeholders to anomymise data can be diffcult to handle.
Training data should be anonymized using “XX” instead of placeholder or tags.
This prevents ensure privacy and compliance with Data Protection Regulations. Rest assured, SYSTRAN prioritizes customer data security, and the platform has robust safety measures.
For instance, we have an automatic training data deletion feature, adjustable at the dataset level. The default value is set to 90 days, but we also offer options for 180 days and never deleting the data. It is possible to change this value after the upload.
アップロード後のデータのクリーニング方法
Automatic data cleaning is performed during the upload and during processing.
The data undergoes two major cleaning steps.
Firstly, duplicates in both source and target segments are removed. Secondly, we work on resolving wrong encodings and eliminate empty sentences from the target or source.
Then during data processing, another filtering and cleaning takes places for mainly the wrongly aligned segments or a wrong language.