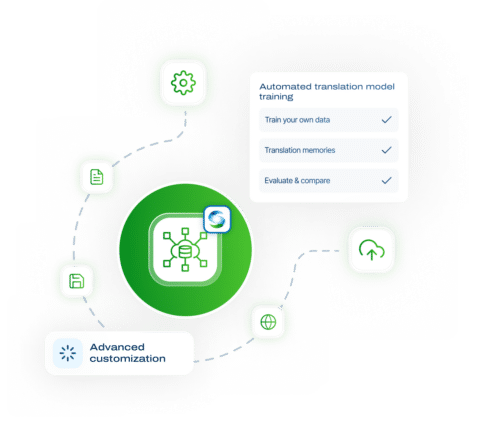
SYSTRAN Model Studio
직접 만들기 변환 모델
자신의 데이터 또는 번역 메모리로 훈련된 자신만의 맞춤형 번역 모델을 만들고 번역 생산성을 크게 향상시키세요!

번역 메모리를 사용하여 적응 번역 모델

EVALUATION
Evaluate & compare with the scoring of your model
You can either add your own test set or choose to allocate some of your training data for testing and evaluation during the data upload phase.
시스트란 자본화 광범위한 카탈로그
처음부터 번역 모델을 구축하는 것은 어려운 작업이 될 수 있다. 운 좋게도, 당신은 처음부터 시작하지 않을 거예요! SYSTRAN은 수십 년 동안 기계 번역 분야의 선두 주자로서 다년간의 전문 지식을 바탕으로 광범위한 번역 모델 카탈로그를 제작해 왔습니다.
SYSTRAN 카탈로그에서 기존 모델을 시작점으로 선택하고 사용자 고유의 데이터로 사용자 정의합니다. 50 개 이상의 언어와 수십 개의 인기 도메인 (법률, 의료, 금융, IT 등)을 사용할 수 있습니다!

WEBINAR
Model Studio : Easy, Quick and Customized Translation Model Training
To improve the quality of your translation output, customization is essential, Model Studio is the solution!
In this webinar, Guersande Chaminade, Product Owner and Stéphanie Labroue, Account Manager at SYSTRAN will teach you how to create your own customized translation models with SYSTRAN Model Studio.

사용자 지정
각 업종에 맞는 번역 솔루션 제공
법의학 및 e-discovery
법 집행을 위한 빅 데이터 분석
다국어 커뮤니케이션 및 협업
글로벌 고객 서비스 및 지원
컨텐츠 로컬라이제이션
NFA 기능이란 무엇입니까?
대상 언어를 평가하는 데 BLEU 점수만 사용합니까?
현재 Model Studio에는 BLEU 점수만 표시됩니다. 우리가 혜성과 같은 다른 도구들을 통합하기 위해 적극적으로 노력하고 있지만, 당분간은 BLEU 점수를 우리의 주요 평가 지표로 사용하는 효율성과 용이성에 초점이 맞춰져 있었다.
Can I deploy more than one model simultaneously? SYSTRAN translate Server & SYSTRAN translate Private Cloud ?
물론이지! 여러 모델을 배포하고 특정 프로젝트에 가장 적합한 모델을 선택할 수 있습니다. 모델을 배포하기 전에 다양한 테스트 파일을 업로드하고 비교하여 각 모델의 성능을 확인할 수 있는 평가 기능을 활용할 수도 있습니다.
최대 3개의 모델을 나란히 비교할 수 있어 요구 사항에 맞는 이상적인 모델을 쉽게 찾을 수 있습니다.
그러나 이 기능을 사용하지 않아도 여러 모델을 쉽게 배포할 수 있습니다.
최대 100만 세그먼트의 한계는 무엇입니까?
모델 스튜디오는 청결함과 견고함 측면에서 최대 100만 문장 쌍을 최대한 활용할 수 있도록 제작되었습니다. 이 제한은 데이터 중복 제거 및 문자 손상 방지 후 데이터에 적용됩니다.
또한 네트워크 문제를 피하기 위해 한 번에 매우 큰 파일을 업로드하지 않는 것이 좋습니다.
훈련 데이터에서 마크업 태그는 어떻게 처리되나요?
현재로서는 태그와 자리 표시자를 처리하는 것이 어려울 수 있습니다. 태그를 포함하는 긴 문장은 처리를 개선하기 위해 삭제될 수 있다. 그러나 태그를 더 잘 처리할 수 있는 솔루션을 적극적으로 개발하고 있으며 이 기능은 2024년에 제공될 예정입니다.
그 동안 CatTools에 태그를 입력하고 이 CatTools가 처리하도록 할 수 있습니다.
교육 데이터를 익명화해야 합니까?
앞에서 본 바와 같이, 그리고 플레이스홀더는 태그로 간주될 수 있으므로, 플레이스홀더를 사용하여 데이터를 변칙화하는 것은 다루기 어려울 수 있다.
학습 데이터는 자리 표시자나 태그 대신 "XX"를 사용하여 익명화해야 합니다.
이를 통해 개인 정보 보호 및 데이터 보호 규정 준수를 보장할 수 없습니다. 안심하세요, SYSTRAN은 고객의 데이터 보안을 우선시하며 플랫폼은 강력한 안전 조치를 가지고 있습니다.
예를 들어, 데이터 세트 수준에서 조정 가능한 자동 교육 데이터 삭제 기능이 있습니다. 기본값은 90일로 설정되어 있지만 180일 동안 옵션을 제공하고 데이터를 삭제하지 않습니다. 업로드 후 이 값을 변경할 수 있습니다.
업로드 후 데이터는 어떻게 정리되나요?
자동 데이터 정리 는 업로드 및 처리 중에 수행됩니다.
데이터는 두 가지 주요 청소 단계를 거칩니다.
첫째, 소스 및 타겟 세그먼트의 중복이 모두 제거됩니다. 둘째, 잘못된 인코딩을 해결하고 대상이나 출처에서 빈 문장을 제거하는 작업을 합니다.
그런 다음 데이터 처리 중에 잘못 정렬된 세그먼트 또는 잘못된 언어에 대해 또 다른 필터링 및 청소가 수행됩니다.